220801월요일 수업. 복습하기.
갓규리의 수업을 바탕으로 이루진 글입니다.
(규리 선생님의 설명, 그리고 만드신 PPT내용을 바탕으로 작성하였습니다.)
데이터 베이스
데이터를 저장하는 구조/ 자료의 모음. 여러 사람에 의해 공유되어 사용될 목적으로 통합하여 관리되는 데이터의 집합이다.
데이터베이스 이전에는 파일시스템을 이용하여 저장하였다.
파일시스템을 안쓰고 데이터베이스를 이용하는것으로 바뀐이유는
1. 데이터중복 (한눈에 파악이 어려움) 2. 데이터 불일치 (중간에 데이터를 바꾸면 데이터를 찾기 힘들어진다. )
DBMS(DataBase Management System) : 파일 시스템이 가진 문제를 해결하기 위해 만들어진것이다. 데이터베이스에 접근하고 이를 관리하기 위해 존재한다.
RDBMS (Relational DBMS) : 관계형 데이터베이스. 내가 배운것이 관계형 데이터 베이스이다. 표 형태로 나타내는 데이터베이스를 생각하면 된다.
반대의 개념인 비관계형은 테이블, 즉 열과 행이 존재하지 않는다.
많은 RDBMS 중에서 나는 MySQL을 배웠다.
데이터베이스의 가장 기본적인 명칭들
- 테이블 (Table, Relation) : 행과 열로 구성된 데이터 모음.
- 열 (Column, Attribute, 속성) : 테이블을 구성하는 각각의 열에 위치한 정보를 말한다.
- 행 (Record, Tuple, 튜플) : 어떤 테이블에서 단일 구조 데이터 항목을 가리킨다. tuple은 중복되면 안된다. 예를들어 김철수의 학번,이름, 학과명 등이 완벽하게 일치하면 안된다. 데이터가 정확하게 중복되었기 때문이다. 한 개의 Column(열)이라도 다르다면 들어갈 수 있겠지만 그렇지 않다면 완벽하게 일치하는 데이터는 들어가면 안된다.
| (tuple↓) / (column→) | |||
- 키(key) : 데이터 베이스에서 튜플(행)을 찾거나 순서대로 정렬할 때 구분하고 정렬의 기준이 되는 속성이다.
- 기본키(Primary Key) : 각 테이블마다 존재하는 고유 id. 메인 키로 한 테이블에서 특정 튜플(행)을 유일하게 구별할 수 있는 속성. Null값과 중복값 불가. 테이블마다 pk는 하나일 수 밖에 없다. (피드백을 받은 부분-감사합니다-) 두개 이상의 column을 묶어서 하나의 pk로 설정할 수 있다.
- 외래키(Foreign key) : 어떤 테이블의 기본키를 참조하는 속성. 속성 이름은 달라도 되는데, 그 안의 값은 동일해야 한다.
MySQL
가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템(RDBMS), 오픈소스, 윈도우,Mac, 리눅스 등 다양한 운영체제에서 사용 가능하다. 오라클과 비등하게 사용되는것을 통계치로 확인 할 수있다. 오라클은 자바기반으로 많은 연동이 되어있기 때문에 자바를 모르는 나는 오라클도 모른다.
설치를 통해서 내 로컬 컴퓨터에서 이용하거나, Linux에서 이용하면 된다.
https://dev.mysql.com/downloads/mysql/ 이 주소에서 다운로드 받았다. 다운로드를 안내하는것이 정리의 목적이 아니기에 생략하겠다.
서버들어가서 설치해도된다. (나는 puTTY이용 - 네이버 클라우드 플랫폼 서비스를 이용해서 개인서버를 만들어두었다-.)
apt-get update
sudo apt-get install mysql-sever
mysql -u root -p패스워드 치라는 곳에서는 엔터키를 눌러주면 된다. 설치끝나고 exit; 로 나오면 된다.
로컬과 서버 둘다 설치한 이유는, 나는 오늘 처음 배우는데 바로 command line client를 이용하기 보다 로컬에서 설치한 mysql로 하는것이 더 빠른 습득을 할 수있다고 선생님이 말해주셨기 때문이다.
(피드백으로 내용추가-감사또감사..-) 로컬에서 MySql을 설치하면 로컬에서 사용할 수 있다.
우리가 node.js를 배울때 vscode로 실행하여 localhost에서 확인한 것처럼, 내가 서버에 설치하면 서버에서 사용이 가능하다. '공인ip:nnnn' 에서 접속해 확인했듯이 사용 할 수 있는것이다.
local instance MySQL80를 실행하고 왼쪽 네비게이터 바에서 Schemas를 통해서 뭐가 있나 살펴 볼 수있다.
SQL 공통
# 데이터베이스 목록보기
show databases;
: (피드백으로 수정!) 전체 데이터베이스 목록을 볼 수 있다. (ctrl + enter 로 실행하는거 잊지말것!, ctrl + enter는 workbench에서 한 줄씩 실행할때 사용한다. 콘솔에서 사용시에는 그냥 enter를 사용해도 된다.)
#데이터베이스 이용하기
use 데이터베이스명;
( :나의 경우 use sesac;을 치면 이용할 수 있다. )
#테이블 목록 보기
show tables;
#테이블 구조보기
desc 테이블명;
SQL문 (Structured Quert Language)
SQL문은 크게 3가지로 구분 할 수 있다.
DDL - DML - DCL 으로 구성되어있다.
DDL (Data Manipulation Language)
데이터베이스를 정의하는 언어이다. 아래의 4가지의 종류와 역할들을 살펴볼 수 있다. 데이터의 전체적인 틀을 관리한다. column등을 생성해서 table이름이나, 전체적으로 삭제-초기화-하는 등의 작업을 한다.
CREATE : 데이터베이스, 테이블 등을 생성하는 역할을 한다.
ALTER : 테이블을 수정하는 역할을 한다.
DROP : 데이터베이스, 테이블을 삭제하는 역할을 한다.
TRUNCATE : 테이블을 초기화 시키는 역할을 한다.
→ Create
데이터베이스 만들기>
CREATE DATABASE 이름 DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
테이블 만들기>
CREATE TABLE 테이블명 (
필드1 값형식,
필드2 값형식
);필드는 column명이다. 어떤 값이 들어올지 형식을 적는것이 값형식 부분이다. 형식은 여러 개 적을 수 있다.
1. MySQL WorkBench에서 CREATE DATABASE sesac; 으로 먼저 데이터 베이스를 만들어준다.
ctrl + enter로 생성되는것을 알 수 있다. 그리고 왼쪽의 Navigator에서 새로고침을 눌러주면 내가 설정한 sesac데이터베이스를 확인 할 수있다.

데이터베이스 실행 후, ctrl a. 그 후 sesac 을 우클릭하면 refresh all 이 나온다. 혹시 안뜬다면 USE sesac;을 타이핑하여 설정한다.
위의 캡쳐처럼 선택된 데이터는 볼드체로 확인 할 수 있다.
- create table : table을 만들겠다는 것이다. user는 내가 만든 table의 이름이다.
- varchar(10) : 10글자까지 허용하겠다.
- not null : 문자그대로 null은 허용하지 않겠다는 뜻이다.
> 숫자형 데이터 형식
대부분 int를 많이 사용한다. 그 외에도 tinyint, smallint, mediumint등이 있다.
> 날짜형 데이터 형식
Date, Time, Datetime, Timestamp, year 등이 있다.
Timestamp : 정확한 시간이 계속 찍힘. ex) 구글에 비번 변경한 후에 예전 비밀번호로 로그인을 시도하면 ' 1시간 전에 변경한 비밀번호 입니다.' 뜬다. 이런식으로 사용된다고 한다.
나머지는 영어그대로의 값들을 사용한다. 날짜, 시간, 날짜와 시간, 년도 등을 나타낸다.
→ Alter
1. column 삭제
alter table 테이블명 drop column 컬럼명;2. 컬럼(column) 추가
alter table 테이블명 add 컬럼명 타입3. 컬럼 속성 변경
alter table 테이블명 modify 컬럼명 타입;alter는 특정 컬럼을 수정하거나 추가 할 때 많이 사용한다.
→ Drop, Truncate
Drop : 테이블 삭제하기.
drop table 테이블명;Truncate : 테이블 초기화하기.
truncate table 테이블명;Truncate는 말그대로 초기화이기 때문에 한 번 날리면 복구하지 못한다. 따라서 복구 시스템을 따로 사용하지 않는한 쓰지 않는것이 좋다.
DML(data Munipulation Language)
데이터베이스의 내부 데이터를 관리하기 위한 언어. 데이터에 관한 것들을 관리한다. 추가, 수정, 삭제 등
SELECT : 데이터를 조회
INSERT : 테이블에 데이터를 추가
UPDATE : 테이블에서 데이터를 수정
DELETE : 테이블에서 데이터를 삭제
CRUD(Create, Read, Update, Delete) : 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 처리 기능.
DML-INSERT
테이블에 데이터를 추가하기 위해 사용한다.
INSERT INTO 테이블명(필드1, 필드2, 필드3) VALUES (값1, 값2, 값3);
INSERT INTO 테이블명 VALUES(값1, 값2, 값3);위의 경우 매칭해서 넣어주면 되고, 아래는 모든컬럼들을 순서대로 넣고싶을때 사용한다.
DML - SELECT
데이터를 검색(조회)하기 위해 사용한다.
SELECT*FROM 테이블명;
SELECT*FROM 테이블명 WHERE 필드1 - 조건값1;
SELECT*FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 ASC;
SELECT 필드1, 필드2, 필드3 FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 ASC;
SELECT 필드1, 필드2, 필드3 FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 ASC LIMIT 개수;→ 모든컬럼의 모든데이터 표시. *은 항상 모든 데이터를 표시하겠다는 뜻이다.
→ 그리고 WHERE이하에 우리가 조건을 설정할 수 있다.
→ ORDER BY 는 가져온 친구들을 정렬한다. 이때에 오름차순으로 정렬하고 싶을땐 ASC/ 내림차순으로 정렬하고 싶을땐 DESC를 사용한다.
예시1 ) SELECT * FROM user(테이블명) WHERE name(열, 어트리뷰트)='홍길동';
은 name 이 홍길동인것을 보여달라는것이고 그 결과 user 라는 테이블에서 검색한 값을 보여준다. (아래 캡쳐)
또한 아래와 같은 걸로
SELECT * FROM user WHERE name='홍길동' AND id='id1';처럼 사용이 가능하다.

예시2) SELECT * FROM user WHERE name='홍길동' ORDER BY ID DESC;
로 가져온 값들을 정렬할 수 있다. DESC이므로 내림차순 정렬이 되었음을 알 수 있다. (아래 캡쳐)

SELECT * FROM user ORDER BY ID DESC;→ WHERE 없어도 사용이 가능하다.
예시3) LIMIT로 갯수를 제한해서 보기. (아래 캡쳐) LIMIT 2 는 위에서부터 2개의 데이터만 가져와서 보여준다.

SELECT*FROM user LIMIT 2;이 역시 WHERE 그리고 ODER BY 없이도 사용 가능하다.
예시4) * 대신에 컬럼명을 정확하게 적으면 그 컬럼의 값만 정확하게 가져온다.
SELECT name, birthday FROM user;
DML - UPDATE, DELETE
UPDATE : 데이터를 수정할때 사용한다.
UPDATE 테이블명 SET 필드1=값1 WHERE 필드2=조건2;DELETE : 데이터를 삭제할때 사용한다.
DELETE FROM 테이블명 WHERE 필드1=값;
WHERE 절 - 비교연산자, 논리연산자, 부정연산자, SQL연산자
비교연산자
= : 같다
>, < : 보다 크다, 보다 작다
>=,<= : 보다 크거나 같다, 보다 작거나 같다.
논리 연산자
AND : 앞의 조건과 뒤의 조건이 TRUE가되면 결과도 TRUE
OR : 앞의 조건과 뒤의 조건 중 하나라도 TRUE라면 결과는 TRUE
NOT : 뒤에 오는 조건과 반대되는 결과를 돌려준다.
부정연산자
!=, ^=, <> : 같지않다
NOT 컬럼명 = : ~와 같지 않다.
SQL연산자
BETWEEN a AND b : a와 b의 값 사이에 있으면 참(a와 b값도 포함한다)
IN(list) : 리스트에 있는 값 중에서 어느 하나라도 일치하면 참
LIKE'비교문자열' : 비교문자열과 형태가 일치하면 사용(%, _ 사용)
IS NULL : NULL 값인 경우
예시1 )
_ : 이걸 사용할때에는 글자수가 일치해야한다. 따라서 내가 3글자에 'X규리'의 값들을 찾기 위해서는 '_규리'로 설정하여 찾는다. 아래 캡쳐의 경우 언더바까지 3개의 문자열이 일치했기 때문에 성이다른 규리들이 나온것이다.

예시2 )
아래 캡쳐와 같이 '%리'는 임의의 문자열, 0개 이상의 문자열을 검색하는 것이므로 X리와 일치하는 모든 값을 찾아준다.
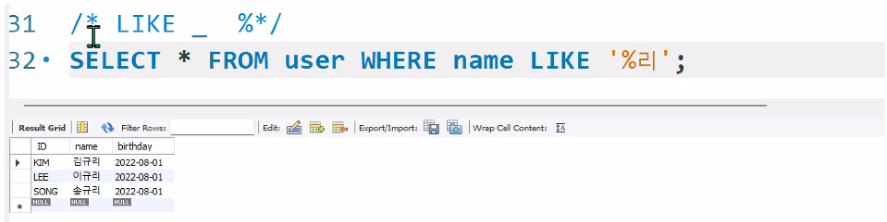
위의 응용으로 만일 이씨 성을 가진 사람을 찾고싶다면 아래와 같이 '이%' 를 이용한다.
SELECT * FROM user WHERE name LIKE '이%';
배우면서 나에게 아쉬웠던 점
오탈자가 너무많아서 로컬에서 실행할때마다 오류가 났다. 특히 문자열을 쓸때 ' ' 를 사용하지 않아서 너무많은 오류가 났다.
많은 오류때문에 수업을 제속도로 따라갈 수 없어서 내용이해를 완전히 하지 못하고 넘어간 것들이 아쉽다. 그렇기에 실습을 할때 다른사람들에게 물어서 하거나, 다른사람들이 올린 코드를 보며 진행했다. 베껴서 진행한것이 많아서 찜찜하다.
또한 마지막 추가실습을 스킵하게 된 점이 아쉽다. 물론 다른사람들이 그 실습을 진행할때 나는 모르는 것을 이해하기 위해서 수업 ppt와 내가 작성해둔 notion을 보고, 못했던 실습을 진행했다.
딱히 잘한건 없는거같은데, 굳이 따지자면 블로그를 만들어서 복습을 위해 정리했다는 것. 규리쌤의 ppt를 옮긴것도 있지만, 최대한 내가 이해하고 내 언어로 옮기려고 노력했기에 이해가 없이는 힘들었을 것이다. 꾸역꾸역 이해하면서 하게되어 좋았다. 제발 잊어버리지 말자..
*피드백 환영*
1차 피드백 반영 완. 정말 감사합니다! 피드백 환영 왕사랑!